

当我们往黑窗口输入一条SQL给Mysql执行,Mysql 查询优化器会按照一定的规则帮我们对SQL进行重写,优化,本文将会讲解:
条件化简就是我们平时很常见的消除一些冗余的条件,如:
- 移除不必要的括号
- 常量传递
比如:可以转换为 - 等值传递
比如: 可以转换为 - 移除没用的条件
比如:,很明显 b=b肯定是true,5!=5肯定是false,可以转换为,然后可以化简为 - 表达式计算
比如:可以化简为
看完上面的条件化简是不是挺简单的,我们继续往下看:
常量表指的是对该表的查询成本是常量级别的,非常快的。比如表里没有数据或只有一条数据(针对MyIsam存储引擎),或者在Innodb中按照主键等值匹配、按照唯一二级索引等值匹配。在这种情况下,mysql会先把涉及到该表的条件全部替换为常数,然后再分析其余表的查询成本。
举个例子:
因为这里涉及到对table1的常量查询,所以可以把table1匹配的结果直接查出来并替换为常量。
这个地方是要提醒的,因为我之前的理解:这种查询会先采用两表做笛卡尔积之后再匹配查询条件,显然那样的成本是更高的。
首先内连接(inner join)与外连接(left join、right join)的区别在于:
外连接的驱动表,如果无法在被驱动表找到匹配ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表的各字段用NULL填充。
而内连接如果无法在被驱动表找到匹配ON子句中的过滤条件的记录,那么该记录不会加入到结果集中。
如果我们在查询中指定被驱动表的相关列的值不为NULL,那么在这种情况下,内连接与外连接就没有什么区别了。此时mysql查询优化器就可以自由评估不同连接顺序的成本,来选择成本最低的连接顺序。
如:
这里指定了被驱动表t2的n2列不能为null,所以这里的左连接与内连接是等价的,等同于:
在讲解子查询之前,我们新建两张表,表的结构一样,并插入一定量的数据:
不相关标量子查询
比如:
我们看到子查询的查询条件是key3,外查询的查询条件是key1,是不相关的条件。
它的执行计划就和我们正常想的一样,先执行子查询的结果,然后代入到外层查询执行。
标量相关子查询
先从外层s1表获取一条记录,然后将该条记录的值代入到子查询中,如果满足子查询,则加入到结果集中,否则丢弃。然后遍历下一条记录。
以上两种都是正常的执行方式,没有很特殊的优化。
IN子查询优化
比如:
可能我们的想法是先执行子查询,然后将子查询的结果代入外层查询,嗯,我之前也是这么想的。
实际上,mysql在in子查询上做了很多优化。原因是如果in子查询的结果比较少,其实还好,查询效率还是很高的,一旦in子查询的结果比较多,那效率就低了。
所以mysql对此有哪些优化呢?
临时表
临时表:将in子查询的结果写入到一张临时表中,子查询要查询的列可以作为表的主键或唯一索引。
如果in子查询结果集不是很大,那么临时表是基于Memory存储引擎的,如果很大,就会采用基于磁盘的表(采用B+索引),这个边界值由变量或者控制。
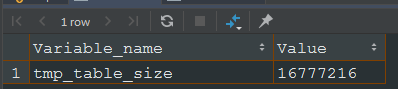
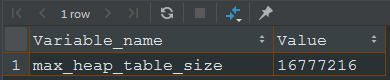
我看了一下,默认值是32MB。
虽然建立临时表也是一个成本,但我们来看一下现在情况,
最后我们要查询的结果集,可以看成是:
1、扫描s1表,取出s1表中key1列的值,看是否存在于临时表中。
2、扫描临时表,把子查询的结果分别去s1表中找出key1=xxx的记录
也就是说上边的查询相当于s1表与临时表的内连接。
其中materialized_table 就是我们创建的临时表,这个过程在mysql中叫做物化,m_val就是物化表中的存储common_field值的列名。
当上述in查询优化为内连接后,mysql就可以评估不同的连接方式的成本从而选择成本更低的连接查询方式啦。
不过你发现没有,如果单纯地认为,in子查询可以转换为内连接,是有问题的。
问题1:如果临时表中的值不是唯一的(就是说同一个common_field值存在多个),那么在in子查询中不会有问题,而在内连接中,就有可能出现相同的两条数据。这是不对的。所以我们需要对临时表进行去重。在Mysql中,为了去除重复列导致结果不对的问题还提出了一个半连接的概念(semi-join,当然这是一种优化手段,我们写sql的时候是用不到的),
半连接就是用来解决重复列的问题,它只考虑驱动表中的数据是否存在于被驱动表中,而不关注有多少条匹配。
半连接的实现方法
为了落地半连接这个概念,会有几种不同的实现方法:
- 1、Table pullout (表上拉),这种主要针对子查询的列是主键或唯一索引列,就是我们前面说的最好的情况,就是子查询的列是不重复的,那么直接改为内连接就可以了。
- 2、DuplicateWeedout execution strategy(重复值消除),这也是我们前面说过的,既然子查询有重复值,那我们就消除重复值呗。如果子查询只有一列,那我们可以将这一列作为临时表的主键,就可以消除重复值了,消除后就同第一种方案了。
- 3、LooseScan execution strategy (松散索引扫描)
这种情况主要针对in子查询的查询条件是索引列的情况。如:
子查询中的key1列是索引列,可以把s2作为驱动表,通过扫描key1列的索引,取key1列不同的值到s1表中匹配数据记录。
- 4、FirstMatch execution strategy (首次匹配)
这个就是半连接在关联表时的语义实现,扫描驱动表,取出一条驱动表中的数据,到被驱动表中匹配,当匹配到第一条之后就将该条数据加入到结果集中。
半连接的使用条件:
如果子查询后有or条件,或者是not in,子查询中有union,有聚集函数等情况就无法使用半连接进行优化了,这个要记住。
另外,如果in子查询不符合半连接的条件,mysql会在以下两次策略中选择成本更低的方案:
1、将子查询物化之后再执行查询
2、执行IN to EXISTS转换(因为任何in子查询都可以转换为exsits查询)
小结
了解Mysql 查询优化器的优化手段有利于我们对SQL执行计划的理解。你可以结合Mysql基于成本的优化加深理解。

